YARN and the Hadoop Ecosystem
The new Apache Hadoop YARN resource manager is introduced in this
chapter. In addition to allowing non-MapReduce tasks to work within a Hadoop
installation, YARN provides several other advantages over the previous version
of Hadoop including better scalability, cluster utilization, and user agility.
YARN also brings with it several new services that separate it
from the standard Hadoop MapReduce model. A new ResourceManger acting as a pure
resource scheduler is the sole arbitrator of cluster resources. User
applications, including MapReduce jobs, ask for specific resource requests via
the new ApplicationMaster component, which in in-turn negotiates with the
ResourceManager to create an application container within the cluster.
By incorporating MapReduce as a YARN framework, YARN also provides
full backward compatible with existing MapReduce tasks and applications.
Beyond
MapReduce
The Apache Hadoop ecosystem continues to grow beyond the simple
MapReduce job. Although MapReduce is still at the core of many Hadoop 1.0
tasks, the introduction of YARN has expanded the capability of a Hadoop
environment to move beyond the basic MapReduce process.
The basic structure of Hadoop with Apache Hadoop MapReduce v1
(MRv1) can be seen in Figure 2.1. The two core services, HDFS and MapReduce, form the
basis for almost all Hadoop functionality. All other components are built
around these services and must use MapReduce to run Hadoop jobs.
Figure 2.1. The Hadoop 1.0
ecosystem, MapReduce and HDFS are the core components, while other are built
around the core.

Apache
Hadoop provides a basis for large scale MapReduce processing and has spawned a
big data ecosystem of tools, applications, and vendors. While MapReduce methods
enable the users to focus on the problem at hand rather than the underlying
processing mechanism, they do limit some of the problem domains that can run in
the Hadoop framework.
To
address these needs, the YARN (Yet Another Resource Negotiator) project was
started by the core development team to give Hadoop the ability to run
non-MapReduce jobs within the Hadoop framework. YARN provides a generic
resource management framework for implementing distributed applications.
Starting with Apache Hadoop version 2.0, MapReduce has undergone a complete
overhaul and is now re-architected as an application on YARN to be called
MapReduce version 2 (MRv2). YARN provides both full compatibility with existing
MapReduce applications and new support for virtually any distributed
application. Figure 2.2illustrates
how YARN fits into the new Hadoop ecosystem.
Figure 2.2. YARN adds a more
general interface to run non-MapReduce jobs within the Hadoop framework
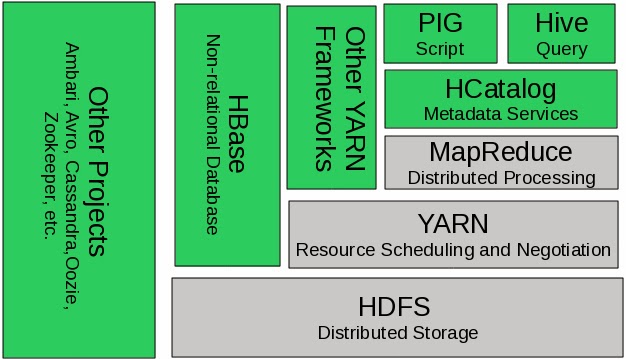
The
introduction of YARN does not change the capability of Hadoop to run MapReduce
jobs. It does, however, position MapReduce as merely one of the application
frameworks within Hadoop, which works the same as it did in MRv1. The new
capability offered by YARN is the use of new non-MapReduce frameworks that add
many new capabilities to the Hadoop ecosystem.
The MapReduce Paradigm
The MapReduce processing model consists of two separate steps. The
first step is an embarrassingly parallel map phase where input data is split
into discreet chunks that can be processed independently. The second and final
step is a reduce phase where the output of the map phase is aggregated to
produce the desired result. The simple, and fairly restricted, nature of the
programming model lends itself to very efficient and extremely large-scale
implementations across thousands of low cost commodity servers (or nodes).
When
MapReduce is paired with a distributed file-system such as Apache Hadoop HDFS
(Hadoop File System), which can provide very high aggregate I/O bandwidth
across a large cluster of commodity servers, the economics of the system are
extremely compelling—a key factor in the popularity of Hadoop.
One of
the keys to Hadoop performance is the lack of data motion where
compute tasks are moved to the servers on which the data reside and not the
other way around (i.e., large data movement to compute servers is minimized or
eliminated). Specifically, the MapReduce tasks can be scheduled on the same
physical nodes on which data are resident in HDFS, which exposes the underlying
storage layout across the cluster. This design significantly reduces the network
I/O patterns and keeps most of the I/O on the local disk or on a neighboring
server within the same server rack.
Apache Hadoop
MapReduce
To understand the new YARN process flow, it will be helpful to
review the original Apache Hadoop MapReduce design. As part of the Apache
Software Foundation, Apache Hadoop MapReduce has evolved and improved as an
open-source project. The project is an implementation of the MapReduce
programming paradigm described above. The Apache Hadoop MapReduce project
itself can be broken down into the following major facets:
• The MapReduce framework, which is the run-time implementation of
various phases such as the map phase, the sort/shuffle/merge aggregation and
the reduce phase.
• The MapReduce system, which is the back-end infrastructure
required to run the user’s MapReduce application, manage cluster resources,
schedule thousands of concurrent jobs etc.
This separation of concerns has significant benefits, particularly
for end-users where they can completely focus on their application via the API
and let the combination of the MapReduce Framework and the MapReduce System
deal with the complex details such as resource management, fault-tolerance, and
scheduling.
The current Apache Hadoop MapReduce system is composed of the
several high level elements as shown in Figure 2.3. The
master process is the JobTracker, which is the clearing house for all MapReduce
jobs on in the cluster. Each Node has a TaskTracker process that manages tasks
on the individual node. The TaskTrakers communicate with and are controlled by
the JobTracker.

The
JobTracker is responsible for resource management (managing the worker server nodes i.e.
TaskTrackers), tracking resource
consumption/availability and
also job life-cycle management (scheduling individual tasks of the
job, tracking progress, providing fault-tolerance for tasks. etc).
The TaskTracker has simple responsibilities—launch/teardown tasks
on orders from the JobTracker and provide task-status information to the
JobTracker periodically.
The Apache Hadoop MapReduce framework has exhibited some growing
pains. In particular, with regards to the JobTracker, several aspects including
scalability, cluster utilization, capability for users to control upgrades to
the stack, i.e., user
agility and,
support for workloads other than MapReduce itself have been identified as
desirable features.
The Need for Non-MapReduce Workloads
MapReduce is great for many applications, but not everything;
other programming models better serve requirements such as graph processing
(e.g., Google Pregel/Apache Giraph) and iterative modeling using Message
Passing Interface (MPI). As is often the case, much of the enterprise data is
already available in Hadoop HDFS and having multiple paths for processing is critical
and a clear necessity. Furthermore, since MapReduce is essentially
batch-oriented, support for real-time and near real-time processing has become
an important issue for the user base. A more robust computing environment
within Hadoop enables organizations to see an increased return on the Hadoop
investments by lowering operational costs for administrators, reducing the need
to move data between Hadoop HDFS and other storage systems, providing other
such efficiencies.
Addressing Scalability
The processing power available in data-centers continues to
increase rapidly. As an example, consider the additional hardware capability
offered by a commodity server over a three-year period:
• 2009
– 8 cores, 16GB of RAM, 4x1TB disk
• 2012
– 16+ cores, 72GB of RAM, 12x3TB of disk.
These new servers are often available at the same price-point as
those of previous generations. In general, servers are twice as capable today
as they were 2-3 years ago—on every single dimension. Apache Hadoop MapReduce
is known to scale to production deployments of approximately 5000 server nodes
of 2009 vintage. Thus, for the same price the number of CPU cores, amount of
RAM, and local storage available to the user will put continued pressure on the
scalability of new Apache Hadoop installations.
Improved Utilization
In the current system, the JobTracker views the cluster as
composed of nodes (managed by individual TaskTrackers) with distinct map slots
and reduce slots, which are not fungible. Utilization issues occur because maps slots might be
‘full’ while reduce slots are empty (and vice-versa). Improving this situation
is necessary to ensure the entire system could be used to its maximum capacity
for high utilization and applying resources when needed.
User Agility
In real-world deployments, Hadoop is very commonly offered as a
shared, multi-tenant system. As a result, changes to the Hadoop software stack
affect a large cross-section of, if not the entire, enterprise. Against that
backdrop, users are very keen on controlling upgrades to the software stack as
it has a direct impact on their applications. Thus, allowing multiple, if
limited, number of versions of the MapReduce framework is critical for Hadoop.
Apache Hadoop
YARN
The fundamental idea of YARN is to split up the two major
responsibilities of the JobTracker, in other words resource management and job
scheduling/monitoring, into separate daemons: a global ResourceManager and
per-application ApplicationMaster (AM). The ResourceManager and per-node slave,
the NodeManager (NM), form the new, and generic, operating system for managing applications
in a distributed manner.
The
ResourceManager is the ultimate authority that arbitrates resources among all
the applications in the system. The per-application ApplicationMaster is, in
effect, a framework specific entity
and is tasked with negotiating resources from the ResourceManager and working
with the NodeManager(s) to execute and monitor the component tasks.
The ResourceManager has a pluggable scheduler component, which is
responsible for allocating resources to the various running applications
subject to familiar constraints of capacities, queues etc. The Scheduler is a pure
scheduler in the sense that it performs no
monitoring or tracking of status for the application, offering no guarantees on
restarting failed tasks either due to application failure or hardware failures.
The scheduler performs its scheduling function based on the resource
requirements of
an application by using the abstract notion of a resource
container, which incorporates resource dimensions
such as memory, CPU, disk, network etc.
The NodeManager is the per-machine slave, which is responsible for
launching the applications’ containers, monitoring their resource usage (CPU,
memory, disk, network), and reporting the same to the ResourceManager.
The per-application ApplicationMaster has the responsibility of
negotiating appropriate resource containers from the Scheduler, tracking their
status and monitoring for progress. From the system perspective, the
ApplicationMaster itself runs as a normal container. An architectural view of YARN is provided in Figure 2.4.

One of the crucial implementation details for MapReduce within the
new YARN system is the reuse of the existing MapReduce framework without any
major surgery. This step was very important to ensure compatibility for existing
MapReduce applications and users.
YARN
Components
By adding new functionality, YARN brings in new components into
the Apache Hadoop workflow. These components provide a finer grain of control
for the end user and at the same time offer more advanced capabilities to the
Hadoop ecosystem.
Resource Manager
As mentioned, the YARN ResourceManager is primarily a pure
scheduler. It is strictly limited to
arbitrating available resources in the system among the competing applications.
It optimizes for cluster utilization (keeps all resources in use all the time)
against various constraints such as capacity guarantees, fairness, and SLAs. To
allow for different policy constraints the ResourceManager has a pluggable
scheduler that enables different algorithms such
as capacity and fair scheduling to be used as necessary.
ApplicationMaster
An
important new concept in
YARN is the ApplicationMaster. The ApplicationMaster is, in effect, an instance of a framework-specific library and is responsible for negotiating
resources from the ResourceManager and working with the NodeManager(s) to
execute and monitor the containers and their resource consumption. It has the
responsibility of negotiating appropriate resource containers from the ResourceManager,
tracking their status and monitoring progress.
•
Scale: The Application Master provides much of the functionality of the
traditional ResourceManager so that the entire system can scale more
dramatically. Simulations have shown jobs scaling to 10,000 node clusters
composed of modern hardware without significant issue. As a pure scheduler the
ResourceManager does not, for example, have to provide fault-tolerance for
resources across the cluster. By shifting fault tolerance to the
ApplicationMaster instance, control becomes local and not global. Furthermore,
since there is an instance of an ApplicationMaster per application, the
ApplicationMaster itself isn’t a common bottleneck in the cluster.
• Open:
Moving all application framework specific code into the ApplicationMaster
generalizes the system so that we can now support multiple frameworks such as
MapReduce, MPI and Graph Processing.
• Move all complexity (to the extent possible) to the
ApplicationMaster while providing sufficient functionality to allow
application-framework authors sufficient flexibility and power.
• Since it is essentially user-code, do not trust the
ApplicationMaster(s). In other words. no ApplicationMaster is a privileged
service.
• The YARN system (ResourceManager and NodeManager) has to protect
itself from faulty or malicious ApplicationMaster(s) and resources granted to
them at all costs.
It’s useful to remember that, in reality, every application has
its own instance of an ApplicationMaster. However, it’s completely feasible to
implement an ApplicationMaster to manage a set of applications (e.g.,
ApplicationMaster for Pig or Hive to manage a set of MapReduce jobs).
Furthermore, this concept has been stretched to manage long-running services,
which manage their own applications (e.g., launch HBase in YARN via a
hypothetical HBaseAppMaster).
Resource Model
YARN supports a very general resource model for applications. An
application (via the ApplicationMaster) can request resources with highly
specific requirements such as:
•
Amount of Memory
• CPUs
(number/type of cores)
•
Eventually resources like disk/network I/O, GPUs, etc.
ResourceRequest and
Containers
YARN is designed to allow individual applications (via the
ApplicationMaster) to utilize cluster resources in a shared, secure and
multi-tenant manner. It also remains aware of cluster topology in order to efficiently schedule and
optimize data access (i.e., reduce data motion for applications to the extent
possible).
In order to meet those goals, the central Scheduler (in the
ResourceManager) has extensive information about an application’s resource
needs, which allows it to make better scheduling decisions across all
applications in the cluster. This leads us to the ResourceRequest and the
resulting Container.
Essentially an application can ask for specific resource requests
via the ApplicationMaster to satisfy its resource needs. The Scheduler responds
to a resource request by granting a container, which satisfies the requirements
laid out by the ApplicationMaster in the initial ResourceRequest.
<resource-name, priority, resource-requirement,
number-of-containers>
• Resource-name is either hostname, rackname or * to indicate no
preference. Future plans may support even more complex topologies for virtual
machines on a host, more complex networks, etc.
•
Priority is intra-application priority for this request (not across multiple
applications).
• Resource-requirement is required capabilities such as memory,
CPU, etc. (currently YARN only supports memory and CPU).
Essentially, the Container is the resource allocation, which is
the successful result of the ResourceManager granting a specific
ResourceRequest. A Container grants rights to an application to use a specific
amount of resources (memory, CPU etc.) on a specific host.
The
ApplicationMaster has to take the Container and present it to the NodeManager
managing the host, on which the container was allocated, to use the resources
for launching its tasks. For security reasons, the Container allocation is
verified, in the secure mode, to ensure that ApplicationMaster(s) cannot
fake allocations in
the cluster.
Container Specification
While a Container, as described above, is merely a right to use a
specified amount of resources on a specific machine (NodeManager) in the
cluster, the ApplicationMaster has to provide considerably more information to
the NodeManager to actually launch the
container. YARN allows applications to launch any process and, unlike existing
Hadoop MapReduce, it isn’t limited to Java applications.
•
Environment variables.
• Local resources necessary on the machine prior to launch, such
as jars, shared-objects, auxiliary data files etc.
•
Security-related tokens.
This design allows the ApplicationMaster to work with the
NodeManager to launch containers ranging from simple shell scripts to
C/Java/Python processes on Unix/Windows to full-fledged virtual machines.
hi ,you have gathered a valuable information on Hadoop...., and i am much impressed with the information and it is useful for Hadoop Learners.
ReplyDeleteHadoop Training in hyderabad
Actually, you have explained the technology to the fullest. Thanks for sharing the information you have got. It helped me a lot. I experimented your thoughts in my training program.
ReplyDeleteHadoop Training Chennai
Hadoop Training in Chennai
Big Data Training in Chennai
interesting blog. It would be great if you can provide more details about it. Thanks you
ReplyDeleteHadoop Certification in Chennai
interesting blog.
ReplyDeleteAngularjs training in chennai
nice..
ReplyDeleteMSBI training in chennai
Great content. I really enjoyed while reading this content with useful information, keep sharing.
ReplyDeletedot net training in chennai
Interesting blog. It would be great if you can provide more details about it. Thanks you
ReplyDeletephp training in chennai
Definitely, what a fantastic website and informative posts, I will bookmark your website.Have an awsome day!
ReplyDeletePowershell Online Training Real Time Support From India
Sap BW Hana Online Training Class
Sap Hana Online Certification Training Course for Professional
Sap Fiori Online Training Material From Hyderabad India
Sap SD Online Training Classes With Real Time Support From India
SCCM 2012 Online Training Course Free With Certficate
Excellent article. Very interesting to read. I really love to read such a nice article. Thanks! keep rocking. Big Data Hadoop Online Training
ReplyDeleteA fantastic read about hadoop.Thanks a lot very much for the high your blog post quality and results-oriented help. I won’t think twice to endorse to anybody who wants and needs support about this area.
ReplyDeleteJava Training Institute Bangalore
Ciitnoida provides Core and java training institute in
ReplyDeletenoida. We have a team of experienced Java professionals who help our students learn Java with the help of Live Base Projects. The object-
oriented, java training in noida , class-based build
of Java has made it one of most popular programming languages and the demand of professionals with certification in Advance Java training is at an
all-time high not just in India but foreign countries too.
By helping our students understand the fundamentals and Advance concepts of Java, we prepare them for a successful programming career. With over 13
years of sound experience, we have successfully trained hundreds of students in Noida and have been able to turn ourselves into an institute for best
Java training in Noida.
java training institute in noida
java training in noida
best java training institute in noida
java coaching in noida
java institute in noida
BCA Colleges in Noida
ReplyDeleteCIIT Noida provides Sofracle Specialized B Tech colleges in Noida based on current industry standards that helps students to secure placements in their dream jobs at MNCs. CIIT provides Best B.Tech Training in Noida. It is one of the most trusted B.Tech course training institutes in Noida offering hands on practical knowledge and complete job assistance with basic as well as advanced B.Tech classes. CIITN is the best B.Tech college in Noida, greater noida, ghaziabad, delhi, gurgaon regoin .
At CIIT’s well-equipped Sofracle Specialized M Tech colleges in Noida aspirants learn the skills for designing, analysis, manufacturing, research, sales, management, consulting and many more. At CIIT B.Tech student will do practical on real time projects along with the job placement and training. CIIT Sofracle Specialized M.Tech Classes in Noida has been designed as per latest IT industry trends and keeping in mind the advanced B.Tech course content and syllabus based on the professional requirement of the student; helping them to get placement in Multinational companies (MNCs) and achieve their career goals.
MCA colleges in Noida we have high tech infrastructure and lab facilities and the options of choosing multiple job oriented courses after 12th at Noida Location. CIIT in Noida prepares thousands of engineers at reasonable B.Tech course fees keeping in mind training and B.Tech course duration and subjects requirement of each attendee.
Engineering College in Noida"
Thanks for sharing your blog..Its more interesting and impressive..Upload more blog like this.Great.. Have a more responsibility and execution. good job
ReplyDeleteAngular JS Training in Chennai
Software Testing Training in Chennai
Android Training in Chennai
Cloud Training in Chennai
Thanks for sharing your blog..Its more interesting and impressive..Upload more blog like this.Great.. Have a more responsibility and execution. good job
Angular JS Training in Chennai
Software Testing Training in Chennai
Android Training in Chennai
Cloud Training in Chennai
It’s always so sweet and also full of a lot of fun for me personally and my office colleagues to search your blog a minimum of thrice in a week to see the new guidance you have got.
ReplyDeleteDotnet Training in Chennai | Dotnet Training course in Chennai
Android Training in Chennai |Best Android Training course in Chennai
CCNA Training in Chennai | CCNA Training course in Chennai
MCSE Training in Chennai | MCSE Training course in Chennai
Embedded Systems Training in Chennai |Embedded Systems Training course in Chennai
Matlab Training in Chennai | Matlab Training course in Chennai
C C++ Training in Chennai | C C++ Training course in Chennai
linux Training in Chennai | NO.1 linux Training in Chennai
Unix Training in Chennai | NO.1 Unix Training in Chennai
Sql Training in Chennai | NO.1 Sql Training in Chennai
It’s great to come across a blog every once in a while that isn’t the same out of date rehashed
ReplyDeletematerial. Fantastic read.
Java Training in Chennai |Best
Java Training in Chennai
C C++ Training
in Chennai |Best C C++ Training Institute in Chennai
Data science Course
Training in Chennai |Best Data Science Training Institute in Chennai
RPA Course
Training in Chennai |Best RPA Training Institute in Chennai
AWS Course Training
in Chennai |Best AWS Training Institute in Chennai
Devops Course Training
in Chennai |Best Devops Training Institute in Chennai
Selenium Course Training in
Chennai |Best Selenium Training Institute in Chennai
Java Course Training in Chennai |
Best Java Training Institute in Chennai
I am really thankful for posting such useful information. It really made me understand lot of important concepts in the topic. Keep up the good work!
ReplyDeleteOracle Training in Chennai | Oracle Course in Chennai
Those guidelines additionally worked to become a good way to recognize that other people online have the identical fervor like mine to grasp great deal more around this condition
ReplyDeleteAWS training in chennai | AWS training in annanagar | AWS training in omr | AWS training in porur | AWS training in tambaram | AWS training in velachery
Great blog and also wonderful information.
ReplyDeleteBig Data Hadoop Training In Chennai | Big Data Hadoop Training In anna nagar | Big Data Hadoop Training In omr | Big Data Hadoop Training In porur | Big Data Hadoop Training In tambaram | Big Data Hadoop Training In velachery
very nice post.Thank you....
ReplyDeletebig data hadoop course
best online training for big data and hadoop
big data online course
big data online training
Great article,keep sharing more posts with us.
ReplyDeletethank you...
hadoop admin course
hadoop admin training
Thanks for sharing a very useful content!
ReplyDeletedata science training in chennai
ccna training in chennai
iot training in chennai
cyber security training in chennai
ethical hacking training in chennai
Very Nice Blog…Thanks for sharing this information with us. Here am sharing some information about training institute.
ReplyDeletedevops training in hyderabad
Great post! You explained YARN and Hadoop’s architecture so clearly. Thanks for making these complex concepts easy to grasp and engaging. Keep up the excellent work!
ReplyDeleteonline internship | internship in chennai | online internship for students with certificate | bca internship | internship for bca students | sql internship | online internship for btech students | internship for 1st year engineering students